Este artigo é uma continuação da parte 1; Big Data – Conceitos e os 5 Vs do Big Data. Acompanhe a sequência de artigos sobre Big Data aqui no Blogson.
Neste artigo iremos ver;
- Introdução
- Camadas da Arquitetura de Big Data
- Principais Tecnologias e Componentes
- Acesso, Gerenciamento e Armazenamento de Dados em Ambientes Distribuídos
- Conclusão
Introdução
Na era da informação, os dados desempenham um papel crucial em todos os aspectos da nossa vida, desde a tomada de decisões empresariais até avanços na medicina. No entanto, a quantidade massiva de informações geradas diariamente requer uma abordagem diferente para armazenamento, processamento e análise.
É aí que entra a arquitetura de Big Data. Neste artigo, exploraremos em detalhes as camadas, os componentes e as principais tecnologias envolvidas nessa arquitetura, bem como estratégias para acessar, gerenciar e armazenar dados em um ambiente distribuído.
Camadas da Arquitetura de Big Data
A arquitetura de Big Data é composta por várias camadas, cada uma desempenhando um papel fundamental no ciclo de vida dos dados. Vamos examinar essas camadas em profundidade:
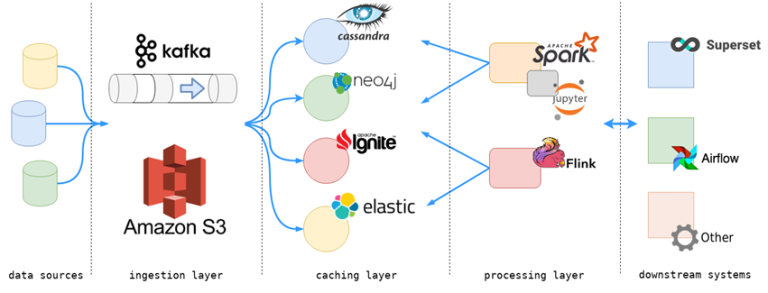
1. Camada de Ingestão (coleta) de Dados: A primeira etapa é a coleta de dados a partir de diversas fontes, como sensores, aplicativos, redes sociais e sistemas de armazenamento. Os componentes-chave nessa camada incluem:
- Apache Flume: Uma ferramenta de ingestão de dados que coleta, agrega e move dados de maneira eficiente para outros componentes do sistema.
- Apache Kafka: Uma plataforma de streaming que permite a ingestão de dados em tempo real, garantindo alta escalabilidade e confiabilidade.
2. Camada de Armazenamento: Após a coleta, os dados são armazenados em sistemas distribuídos. O componente central nessa camada é o Hadoop Distributed File System (HDFS), que divide os dados em blocos e os distribui em clusters de servidores para garantir a redundância e a confiabilidade. O HDFS é essencial para lidar com volumes massivos de dados e é a base para muitas soluções de Big Data.
3. Camada de Processamento: Nesta fase, os dados são processados e transformados em informações valiosas. Tecnologias-chave para o processamento de dados incluem:
- Apache Spark: Uma estrutura de processamento de dados em memória que acelera o processamento em lotes e em tempo real.
- MapReduce: Embora tenha sido substituído pelo Spark em muitos casos, o MapReduce ainda é relevante em algumas aplicações de Big Data.
4. Camada de Consulta e Análise: Após o processamento, os dados são disponibilizados para consulta e análise. Tecnologias populares nesta camada são:
- Apache Hive: Uma ferramenta de consulta de dados que fornece uma linguagem similar ao SQL para análise de dados.
- Apache Impala: Um mecanismo de consulta em tempo real que permite consultas interativas de dados armazenados no Hadoop.
{kind=link}
Principais Tecnologias e Componentes
A arquitetura de Big Data é alimentada por várias tecnologias-chave que tornam possível o processamento de grandes volumes de dados. Algumas dessas tecnologias e componentes incluem:
- Hadoop: É a base de muitas arquiteturas de Big Data e inclui o HDFS para armazenamento e o YARN para gerenciamento de recursos.
- Spark: O Apache Spark é uma estrutura de processamento de dados em memória que é conhecida por sua eficiência no processamento de dados em tempo real.
- MapReduce: Embora tenha sido substituído pelo Spark em muitos casos, o MapReduce ainda é relevante em algumas aplicações de Big Data.
- Apache Cassandra: Um banco de dados NoSQL altamente escalável projetado para lidar com dados distribuídos e de grande volume.
Acesso, Gerenciamento e Armazenamento de Dados em Ambientes Distribuídos
Gerenciar e armazenar dados em ambientes distribuídos requer uma abordagem cuidadosa. Abaixo estão algumas práticas recomendadas:
- Políticas de Segurança: Implementar políticas de segurança rigorosas para proteger os dados, incluindo criptografia, autenticação e autorização.
- Orquestração de Tarefas: Utilizar ferramentas de orquestração, como o Apache Oozie, para agendar e gerenciar tarefas de processamento, garantindo que elas sejam executadas de maneira eficiente.
- Monitoramento e Manutenção: Monitorar a integridade do sistema usando ferramentas como o Nagios ou o Prometheus para garantir que todos os componentes estejam funcionando conforme o esperado.
- Escalabilidade: Planejar para escalabilidade, pois os dados continuarão a crescer. Garantir que a infraestrutura seja capaz de lidar com o aumento dos volumes de dados sem interrupções.
Conclusão
A arquitetura de Big Data é uma revolução no mundo da informação, permitindo que empresas e organizações extraiam insights valiosos de dados em larga escala. Compreender suas camadas, tecnologias e componentes é fundamental para aproveitar ao máximo o poder dos dados e impulsionar a inovação e a tomada de decisões informadas.
À medida que o universo de dados continua a crescer, a arquitetura de Big Data se torna cada vez mais relevante e essencial para empresas e organizações em todo o mundo. Portanto, dominar essas tecnologias e práticas é um passo crucial para o sucesso no mundo dos negócios baseados em dados.